Introduce a per-FS rename lock and new vfsops to manipulate it.
Get this lock while renaming. Also add another relookup() in do_sys_rename,
which is a hack to kludge around some of the worst deficiencies of
ufs_rename.
reviewed-by: pooka (and an earlier rev by ad)
posted on tech-kern with no objections.
- All three functions are included in the kernel by default.
They call a backend function cpu_in_cksum after possibly
computing the checksum of the pseudo header.
- cpu_in_cksum is the core to implement the one-complement sum.
The default implementation is moderate fast on most platforms
and provides a 32bit accumulator with 16bit addends for L32 platforms
and a 64bit accumulator with 32bit addends for L64 platforms.
It handles edge cases like very large mbuf chains (could happen with
native IPv6 in the future) and provides a good base for new native
implementations.
- Modify i386 and amd64 assembly to use the new interface.
This disables the MD implementations on !x86 until the conversion is
done. For Alpha, the portable version is faster.
compiled with -g. For the initial set, netbsd on amd64 grows by around
80KB. This allows much easier use of GDB for post-mortem debugging as
it can understand the layout of data structures. The additional data can
be strip(1)ped off normally for size constraint environments.
Add schedctl(8) - a program to control scheduling of processes and threads.
Notes:
- This is supported only by SCHED_M2;
- Migration of LWP mechanism will be revisited;
Proposed on: <tech-kern>. Reviewed by: <ad>.
For regular (non PIE) executables randomization is enabled for:
1. The data segment
2. The stack
For PIE executables(*) randomization is enabled for:
1. The program itself
2. All shared libraries
3. The data segment
4. The stack
(*) To generate a PIE executable:
- compile everything with -fPIC
- link with -shared-libgcc -Wl,-pie
This feature is experimental, and might change. To use selectively add
options PAX_ASLR=0
in your kernel.
Currently we are using 12 bits for the stack, program, and data segment and
16 or 24 bits for mmap, depending on __LP64__.
via the standard audio interfaces is redirected back to userland as raw
PCM data on /dev/padN.
One example usage is to stream audio to an AirTunes compatible device using
rtunes (http://www.nazgul.ch/dev_rtunes.html), ie:
$ rtunes - < /dev/pad0
$ mpg123 -a /dev/sound1 blah.mp3
Another option is to capture audio output from eg. Real Player, by simply
instructing Real Player to output to /dev/sound1, and running:
$ cat /dev/pad0 > blah.pcm
Rip the transport code completely out of puffs and generalize it
into an independent module which will be used for multiple purposes
in the future. This module is called the Pass-to-Userspace
Transporter (known as "putter" among friends).
This is very much work-in-progress and one dependency with puffs
remains: the request framing format.
The device name is still /dev/puffs, but that will change soon.
Users of puffs need the following in their kernel configs now:
pseudo-device putter
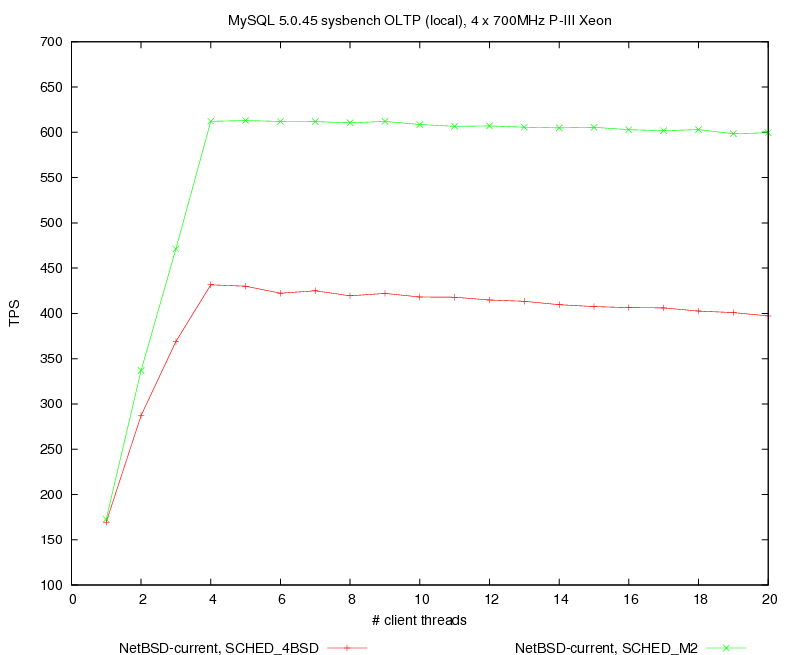
on the original approach of SVR4 with some inspirations about balancing
and migration from Solaris. It implements per-CPU runqueues, provides a
real-time (RT) and time-sharing (TS) queues, ready to support a POSIX
real-time extensions, and also prepared for the support of CPU affinity.
The following lines in the kernel config enables the SCHED_M2:
no options SCHED_4BSD
options SCHED_M2
The scheduler seems to be stable. Further work will come soon.
http://mail-index.netbsd.org/tech-kern/2007/10/04/0001.htmlhttp://www.netbsd.org/~rmind/m2/mysql_bench_ro_4x_local.png
Thanks <ad> for the benchmarks!
For now these just pass through to the current softintr code.
(The naming is different to allow softint/softintr to co-exist for a while.
I'm hoping that should make it easier to transition.)
from the forwarding table's users:
Introduce rt_walktree() for walking the routing table and
applying a function to each rtentry. Replace most
rn_walktree() calls with it.
Use rt_getkey()/rt_setkey() to get/set a route's destination.
Keep a pointer to the sockaddr key in the rtentry, so that
rtentry users do not have to grovel in the radix_node for
the key.
Add a RTM_GET method to rtrequest. Use that instead of
radix_node lookups in, e.g., carp(4).
Add sys/net/link_proto.c, which supplies sockaddr routines for
link-layer socket addresses (sockaddr_dl).
Cosmetic:
Constify. KNF. Stop open-coding LIST_FOREACH, TAILQ_FOREACH,
et cetera. Use NULL instead of 0 for null pointers. Use
__arraycount(). Reduce gratuitous parenthesization.
Stop using variadic arguments for rip6_output(), it is
unnecessary.
Remove the unnecessary rtentry member rt_genmask and the
code to maintain it, since nothing actually used it.
Make rt_maskedcopy() easier to read by using meaningful variable
names.
Extract a subroutine intern_netmask() for looking up a netmask in
the masks table.
Start converting backslash-ridden IPv6 macros in
sys/netinet6/in6_var.h into inline subroutines that one
can read without special eyeglasses.
One functional change: when the kernel serves an RTM_GET, RTM_LOCK,
or RTM_CHANGE request, it applies the netmask (if supplied) to a
destination before searching for it in the forwarding table.
I have changed sys/netinet/ip_carp.c, carp_setroute(), to remove
the unlawful radix_node knowledge.
Apart from the changes to carp(4), netiso, ATM, and strip(4), I
have run the changes on three nodes in my wireless routing testbed,
which involves IPv4 + IPv6 dynamic routing acrobatics, and it's
working beautifully so far.
compatibility with the older ioctls. This avoids stack smashing and
abuse of "struct sockaddr" when ioctls placed "struct sockaddr_foo's" that
were longer than "struct sockaddr".
XXX: Some of the emulations might be broken; I tried to add code for
them but I did not test them.
The major changes are:
+ 4Gb (24XX) card support
+ Rewritten fabric and loop evaluation code
+ New f/w sets
The 4Gb changes required major rototilling, which caused a rewrite of
fabric and loop eval code. The latter can now be set up to tune for
dynamic device arrival/departure if the framework is set up for it,
or to be firm about waiting for devices.
Testing has been principally on amd64, i386 and sparc64 and seems to
not have broken things for me.
from doc/BRANCHES:
idle lwp, and some changes depending on it.
1. separate context switching and thread scheduling.
(cf. gmcgarry_ctxsw)
2. implement idle lwp.
3. clean up related MD/MI interfaces.
4. make scheduler(s) modular.
* dev/ic/ug.c (main code shared by the attachments)
* dev/isa/ug_isa.c (isa attachment)
* dev/acpi/ug_acpi.c (acpi attachment)
That means that ug(4) can now be attached via ACPI.
Thanks to Mihai Chelaru for the good work.
Please note, that <tech-kern> people should note about
file names before commit. Otherwise, function may fail
with errno set to EDIRTY, and return -1. ;)
route_in6, struct route_iso), replacing all caches with a struct
route.
The principle benefit of this change is that all of the protocol
families can benefit from route cache-invalidation, which is
necessary for correct routing. Route-cache invalidation fixes an
ancient PR, kern/3508, at long last; it fixes various other PRs,
also.
Discussions with and ideas from Joerg Sonnenberger influenced this
work tremendously. Of course, all design oversights and bugs are
mine.
DETAILS
1 I added to each address family a pool of sockaddrs. I have
introduced routines for allocating, copying, and duplicating,
and freeing sockaddrs:
struct sockaddr *sockaddr_alloc(sa_family_t af, int flags);
struct sockaddr *sockaddr_copy(struct sockaddr *dst,
const struct sockaddr *src);
struct sockaddr *sockaddr_dup(const struct sockaddr *src, int flags);
void sockaddr_free(struct sockaddr *sa);
sockaddr_alloc() returns either a sockaddr from the pool belonging
to the specified family, or NULL if the pool is exhausted. The
returned sockaddr has the right size for that family; sa_family
and sa_len fields are initialized to the family and sockaddr
length---e.g., sa_family = AF_INET and sa_len = sizeof(struct
sockaddr_in). sockaddr_free() puts the given sockaddr back into
its family's pool.
sockaddr_dup() and sockaddr_copy() work analogously to strdup()
and strcpy(), respectively. sockaddr_copy() KASSERTs that the
family of the destination and source sockaddrs are alike.
The 'flags' argumet for sockaddr_alloc() and sockaddr_dup() is
passed directly to pool_get(9).
2 I added routines for initializing sockaddrs in each address
family, sockaddr_in_init(), sockaddr_in6_init(), sockaddr_iso_init(),
etc. They are fairly self-explanatory.
3 structs route_in6 and route_iso are no more. All protocol families
use struct route. I have changed the route cache, 'struct route',
so that it does not contain storage space for a sockaddr. Instead,
struct route points to a sockaddr coming from the pool the sockaddr
belongs to. I added a new method to struct route, rtcache_setdst(),
for setting the cache destination:
int rtcache_setdst(struct route *, const struct sockaddr *);
rtcache_setdst() returns 0 on success, or ENOMEM if no memory is
available to create the sockaddr storage.
It is now possible for rtcache_getdst() to return NULL if, say,
rtcache_setdst() failed. I check the return value for NULL
everywhere in the kernel.
4 Each routing domain (struct domain) has a list of live route
caches, dom_rtcache. rtflushall(sa_family_t af) looks up the
domain indicated by 'af', walks the domain's list of route caches
and invalidates each one.
{kind=link}