support for specifying an accept filter for a service (mostly as a usage
example, but it can be handy for other things). Manual pages to follow
in a day or so.
OK core@.
Add Wasabi System's WAPBL (Write Ahead Physical Block Logging)
journaling code. Originally written by Darrin B. Jewell while
at Wasabi and updated to -current by Antti Kantee, Andy Doran,
Greg Oster and Simon Burge.
OK'd by core@, releng@.
into two parts so that some of the routines could be used by rump.
Now that rump uses both vfs_subr and vfs_subr2 and there is no
reason to keep two files lying around, re-unite them.
The rule is, if you change scan.l or gram.y, you bump the config(5)
version. If you implement the changes under sys/conf/files or affiliate,
you bump the required version in sys/conf/files or in an appropriate place
to minimise annoyance. If the changes makes new config(1) incompatible
with a previous version of config(5), embed it in config(1) using the
CONFIG_MINVERSION definition along with CONFIG_VERSION.
This has been in the tree for what, 3 years now? It's even documented...
them in the mi "files" file, and remove include statements from md files.
These shouldn't pull in additional kernel code when not in use, so it
shouldn't do any harm except a risk of namespace collisions which
should be easy to fix.
host controller implementations, start with two little functions
which fake up string descriptors (which were inconststent, language
table fetching didn't interoperate with other code in the tree)
Introduce a per-FS rename lock and new vfsops to manipulate it.
Get this lock while renaming. Also add another relookup() in do_sys_rename,
which is a hack to kludge around some of the worst deficiencies of
ufs_rename.
reviewed-by: pooka (and an earlier rev by ad)
posted on tech-kern with no objections.
- All three functions are included in the kernel by default.
They call a backend function cpu_in_cksum after possibly
computing the checksum of the pseudo header.
- cpu_in_cksum is the core to implement the one-complement sum.
The default implementation is moderate fast on most platforms
and provides a 32bit accumulator with 16bit addends for L32 platforms
and a 64bit accumulator with 32bit addends for L64 platforms.
It handles edge cases like very large mbuf chains (could happen with
native IPv6 in the future) and provides a good base for new native
implementations.
- Modify i386 and amd64 assembly to use the new interface.
This disables the MD implementations on !x86 until the conversion is
done. For Alpha, the portable version is faster.
compiled with -g. For the initial set, netbsd on amd64 grows by around
80KB. This allows much easier use of GDB for post-mortem debugging as
it can understand the layout of data structures. The additional data can
be strip(1)ped off normally for size constraint environments.
Add schedctl(8) - a program to control scheduling of processes and threads.
Notes:
- This is supported only by SCHED_M2;
- Migration of LWP mechanism will be revisited;
Proposed on: <tech-kern>. Reviewed by: <ad>.
For regular (non PIE) executables randomization is enabled for:
1. The data segment
2. The stack
For PIE executables(*) randomization is enabled for:
1. The program itself
2. All shared libraries
3. The data segment
4. The stack
(*) To generate a PIE executable:
- compile everything with -fPIC
- link with -shared-libgcc -Wl,-pie
This feature is experimental, and might change. To use selectively add
options PAX_ASLR=0
in your kernel.
Currently we are using 12 bits for the stack, program, and data segment and
16 or 24 bits for mmap, depending on __LP64__.
via the standard audio interfaces is redirected back to userland as raw
PCM data on /dev/padN.
One example usage is to stream audio to an AirTunes compatible device using
rtunes (http://www.nazgul.ch/dev_rtunes.html), ie:
$ rtunes - < /dev/pad0
$ mpg123 -a /dev/sound1 blah.mp3
Another option is to capture audio output from eg. Real Player, by simply
instructing Real Player to output to /dev/sound1, and running:
$ cat /dev/pad0 > blah.pcm
Rip the transport code completely out of puffs and generalize it
into an independent module which will be used for multiple purposes
in the future. This module is called the Pass-to-Userspace
Transporter (known as "putter" among friends).
This is very much work-in-progress and one dependency with puffs
remains: the request framing format.
The device name is still /dev/puffs, but that will change soon.
Users of puffs need the following in their kernel configs now:
pseudo-device putter
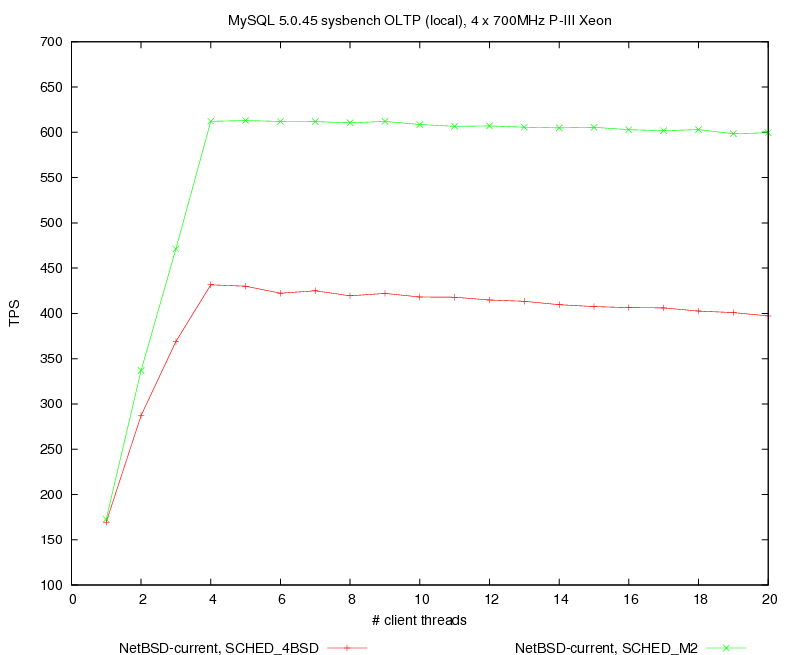
on the original approach of SVR4 with some inspirations about balancing
and migration from Solaris. It implements per-CPU runqueues, provides a
real-time (RT) and time-sharing (TS) queues, ready to support a POSIX
real-time extensions, and also prepared for the support of CPU affinity.
The following lines in the kernel config enables the SCHED_M2:
no options SCHED_4BSD
options SCHED_M2
The scheduler seems to be stable. Further work will come soon.
http://mail-index.netbsd.org/tech-kern/2007/10/04/0001.htmlhttp://www.netbsd.org/~rmind/m2/mysql_bench_ro_4x_local.png
Thanks <ad> for the benchmarks!
For now these just pass through to the current softintr code.
(The naming is different to allow softint/softintr to co-exist for a while.
I'm hoping that should make it easier to transition.)
{kind=link}